Overview
People learning new languages or working on formal writing often want to find more concise wording for the ideas they are trying to express. This problem can be viewed as a reverse dictionary search: given a query Q, which word in the dictionary best describes Q?
Since computers cannot reason about language the way we humans can, one naïve approach to solving this problem involves iterating through the definitions in a dictionary and trying to find the closest match between the definition and the input phrase (perhaps using a similarity measure such as the Jaccard index). Unfortunately, this is not very robust.
Consider the simple, contrived query “travel in a plane”. For this to match the definition of “fly (v): travel in an airplane”, the system has to know that “plane” and “airplane” are synonyms. This can easily be accomplished using a toolkit such as Princeton’s WordNet, which groups words into synonym classes known as synsets (they are kind of like equivalence classes). In this example, “plane”, “airplane”, and “aeroplane” would all be part of the same synset.
While using synsets works for the example “travel in a plane”, it does not scale to more conversational queries. For example, a person who knows that the Concorde is a type of airplane would match the query “travel in a Concorde” to the word “fly”. Unfortunately, WordNet just includes dictionary words, so queries involving proper terms tend to yield poor results. Similarly, the query “travel in a helicopter” would not match “fly” since WordNet does not know that helicopters and airplanes are conceptually-related in that they are both aircraft that fly (but are not synonyms in the dictionary).
Word Vector Models
In addition to matching synonyms of words to find similarities between phrases, a reverse dictionary system needs to know about proper names and even related concepts. Such a model would be difficult for humans to put together given the vast amount of information out there (Wikipedia articles in plain text amount to about 12 GB of data).
Instead, we can use systems to learn such a model from large corpuses of text using unsupervised machine learning algorithms. By analyzing large bodies of text from sources such as Wikipedia and exploiting the fact that similar terms appear closer together, a vector space model where similar words appear close together can be learned. For example, the word “fly” would appear closer to “Concorde” in this space than it would to the word “dance”. To gain some intuition about how a word vector space model looks, I recommend playing with the TensorFlow Embedding Projector and the Word2Vec 10K data set.
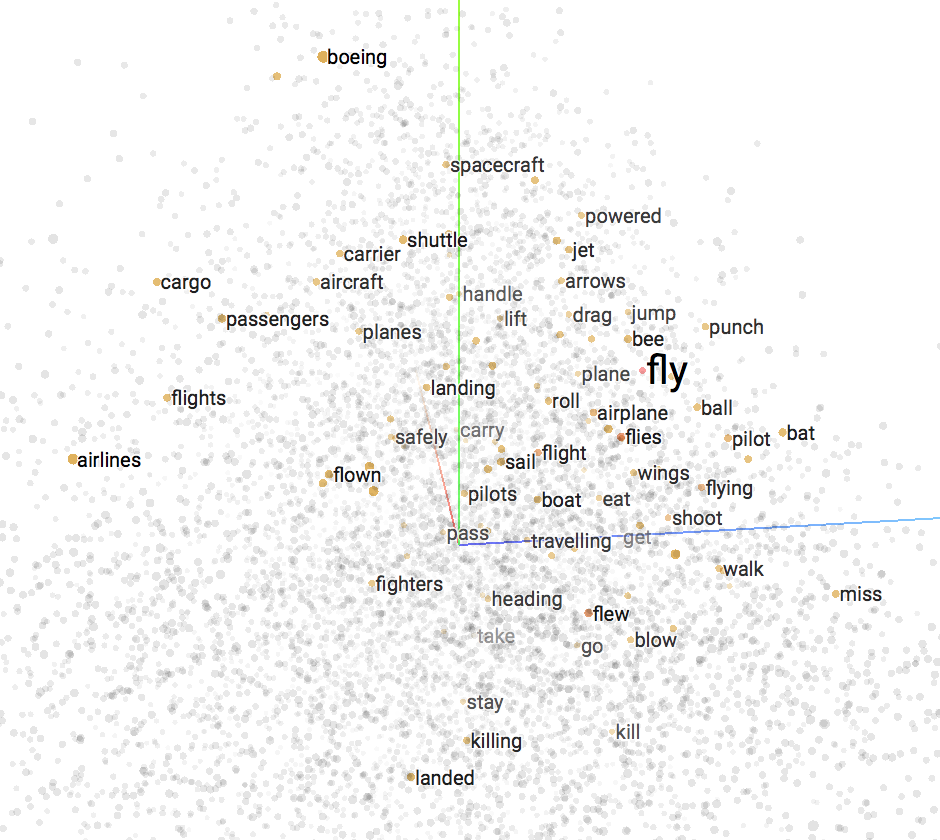
If you search for the word “fly” and select it, you will see that related concepts such as “airplane”, “plane”, and “wings” appear close together!
word2vec
The word2vec system, originally developed at Google, can be used to learn such vector spaces by training neural networks and optimizing probabilities of words appearing together given a context. For example, “fly” would have a higher probability of appearing in a short sentence about Concorde than a short sentence about dancing.
The data required for training is typically extracted from large corpuses of text and pre-processed (lower-cased, stemmed, filtered, and so on). I’ve been using text from Wikipedia articles with good results.
Next, a word2vec model is learned from this data. Since plenty of word2vec tutorials have already been written, I’ll focus on providing a high-level overview on how word2vec models can be used to perform reverse dictionary searches instead of grinding through the details of getting set up.
I found the gensim word2vec library is great for quickly prototyping ideas, but I know TensorFlow can also be used to learn word2vec models. While gensim’s interfaces are written in Python, it uses C and vectorized math under-the-hood to achieve performance comparable to Google’s original C implementation. While training a model can take as long as a day, querying it for word and phrase similarities takes on the order of milliseconds.
Once training completes, the best way to evaluate results is to open a Python REPL and try a few queries. If we simply use our model to compute the distance between <travel, concorde> (stopwords such as “in” are removed) and <fly>, we get a strong correlation of around 0.64:
>>> model.n_similarity(["travel", "concorde"], ["fly"])
>>> 0.6379585If we, instead, try matching the query with <dance>, we get a weak correlation of around 0.17:
>>> model.n_similarity(["travel", "concorde"], ["dance"])
>>> 0.1703189Since we’re dealing with vector spaces and finding similarities between vectors, Cosine similarity is used as a distance measure, where 0 means the vectors are completely unrelated (orthogonal) and 1 means the two vectors are the same.
So, it seems like if we simply try matching the input query to each dictionary word, we can find possible reverse dictionary matches! In practice, we can improve results by matching the query with the word’s definition(s) as well. So in the example above, we would match the query with <fly, travel, airplane>, not merely <fly>. Having a few more related words in there gives us more stable results, especially when dealing with words with multiple meanings.
If we try a few more queries, we find that the top 10 results usually contain the words a user may expect! For example, the query: “travel in helicopter” results in “flying” as the fourth result. The query “to make a saint” returns “canonize” as the second result, and the query “sister of my mother” returns “aunt” as the first result.
Even though the best result isn’t always the first one, I still find this impressive given Wikipedia’s vocabulary contains over 2 million words (very infrequent words are filtered out, otherwise the number would be way higher).
Training Parameters
word2vec algorithms take a wide range of training parameters and results can often be noticeably improved by tweaking their values. Unfortunately, finding the right set of values is a slow process as it involves changing one parameter, waiting as long as a day for training, and then evaluating results. I’ve spent weeks trying different values and re-training the system on my Mac Pro, and I’ve found the following set of parameters works well for reverse dictionary searches:
alpha = 0.04
size = 100
window = 5
sample (rate) = 1e-2
negative (sampling rate) = 15
minimum threshold = 5
use skip gram = False
iterations = 15
use hierarchical sampling = TrueAs always, depending on your problem, your mileage may vary so be sure to experiment with your own data instead of using these values verbatim.
Conclusion
As we have seen, matching word definitions to queries can be used perform reverse dictionary matches in a manner that is robust against differences in language, use of proper nouns, and more!
If you’d like to try out a word2vec-based reverse dictionary matching system, I’ve made an iPhone app that talks to such a cloud-based system running on top of NLTK and gensim (available soon).